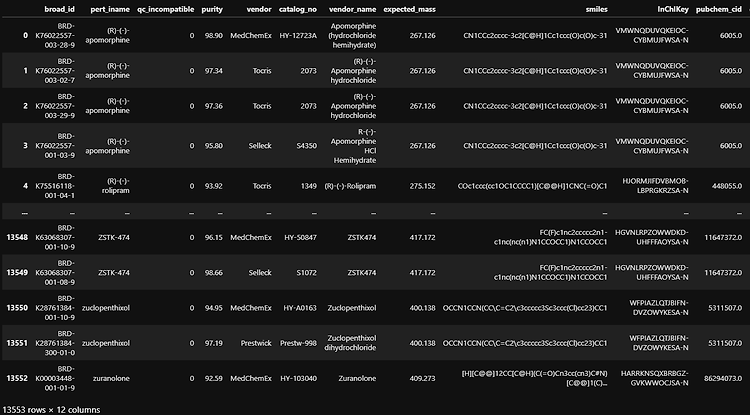
df.drop_duplicates() df 전체의 중복 제거도 할 수 있지만, 열 끼리 중복 제거도 가능하다. 위의 데이터는 pert_iname이라는 열에 중복된 데이터들이 많이 있는데, 여기서 df.drop_duplicates()로 distinct한 값은 몇 개인지 확인할 수 있다. 원래 13553개의 데이터가 중복값을 제외하면 6798개라는 것을 알 수 있다. 다른 방법으로 df.value_counts() 를 이용하면 distinct한 값을 찾아주면서 몇 개가 중복되어있는지 확인할 수 있다.