AI(Artificial Intelligence)/Data Analysis
[웹크롤링] Python으로 웹 크롤링, HTML 파싱, requests, BeautifulSoup 라이브러리 이용
탱젤
2021. 1. 25. 18:04
웹 크롤링으로 href 태그의 값 가져오기 (HTML 파싱)
import requests
from bs4 import BeautifulSoupftp.ensembl.org/pub/current_regulation/homo_sapiens/RegulatoryFeatureActivity/
Index of /pub/current_regulation/homo_sapiens/RegulatoryFeatureActivity/
ftp.ensembl.org

이렇게 생긴 웹 형태에서 데이터 이름만 가져오는 웹 크롤링 실습.
1. requests 라이브러리를 이용해 url get 하기
import requests
from bs4 import BeautifulSoup
res = requests.get('http://ftp.ensembl.org/pub/current_regulation/homo_sapiens/RegulatoryFeatureActivity/')print(res.content)
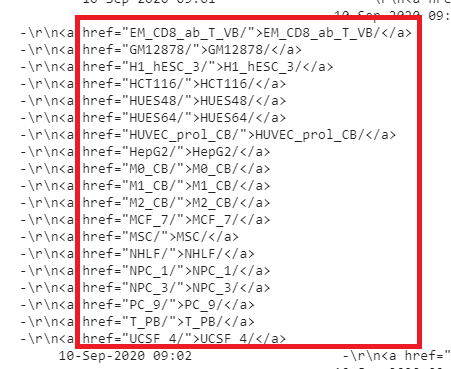
위의 캡쳐 화면에서 href 속성값들을 가져오고 싶다면?
2. BeautifulSoup 라이브러리를 이용해 HTML 데이터 파싱
soup = BeautifulSoup(res.content, 'html.parser')
3. 모든 a 태그 추출 후 href 속성값 가져오기
links = soup.find_all('a') # 모든 a 태그 추출
cell_line = []
for i in links:
href = i.attrs['href']
cell_line.append(href)print(cell_line)
가져오고 싶은 데이터가 list 형태로 불러와진다.
성공~
728x90